A Theory of Web Relativity
by Álvaro Montoro published on
The rel attribute has the potential to take the Internet to the next level… and yet, we usually forget about it.
Imagine a city where people guided themselves by the landmarks and the stores, where there were no directional signs, and where streets and neighborhoods had no names. It may sound like a U2 song, but it is the current state of the web.
The Internet is a vast network of related pages and nodes, but the connections between the elements are void of meaning by default. They lack semantics. A link may connect pages A and B, but what is the relationship between the two? Why are they related? Wouldn’t it be great if there was a way of expressing the relationship between the Internet nodes? Then we wouldn’t have just data; we would have meaningful information. It would take the Internet to a whole new level.
Fortunately, it is possible. Thanks to the rel attribute.
The rel attribute
The rel attribute defines a relationship between the linked resources (one being the document it appears on). And it provides that relationship with meaning, creating a semantic network where the different pieces have a role and a purpose. This detail may go unnoticed by most browser users, but not for the browser itself, assistive technologies, and web crawlers, which can take advantage of this attribute to provide a better experience. Also, savvy web developers can use it to make friendlier sites–we’ll see some examples in the following sections.
The rel attribute is valid in elements that link the document with another resource: <link>, <a>/<area>, and <form>. For simplicity purposes, when talking about <a>, it will include both <a> and <area>.
The supported values and how the browser treats them depend on the element in which the rel attribute appears. This is logical because the relationship can be a how or a what, and it not always makes sense to provide the “how” in some links.
Also, some rel values can be combined to generate more options and provide a more extended experience.
Link Types
Author’s Note: in this article, I will refer to the values/types defined in the IANA link relationship registry and the microformats wiki, but the main focus will be on the values listed in the HTML Living Standard.
I tried to group the types in categories depending on their function and the relationship they express. These are made-up categories to organize my work and they are not official in any way.
Meta types
“Meta links” provide information relevant to the document they appear in: meta information. Things like who’s the author? Where can we find an alternative version of the document? What is the license? Because of their nature, they can appear on <a> or <link> (although sometimes not on both) and never on a <form> tag.
alternate
The “alternate” relationship usually specifies an alternative version of the document itself, but some exceptions exist. It will be the most complex of all the rel meta values because the meaning it provides is heavily conditioned to the context in which it is presented.
If it appears along with the **stylesheet** keyword, the linked file is an alternative stylesheet. It won’t be applied to the document, but it will be ready for when we need it. For example:
<link rel="stylesheet" href="main-styles.css" />
<link rel="stylesheet alternate" href="dark.css" title="dark mode" />When using `stylesheet` with `alternate`, the `` must have a `title` attribute with a short (and non-empty) description.
In this case, the “dark-styles.css” file is loaded asynchronously and not applied to the document. This way, the styles will be available whenever we want to apply them, without having to wait for network or traffic. Some browsers, like Firefox, allow switching between styles, facilitating the process for users:
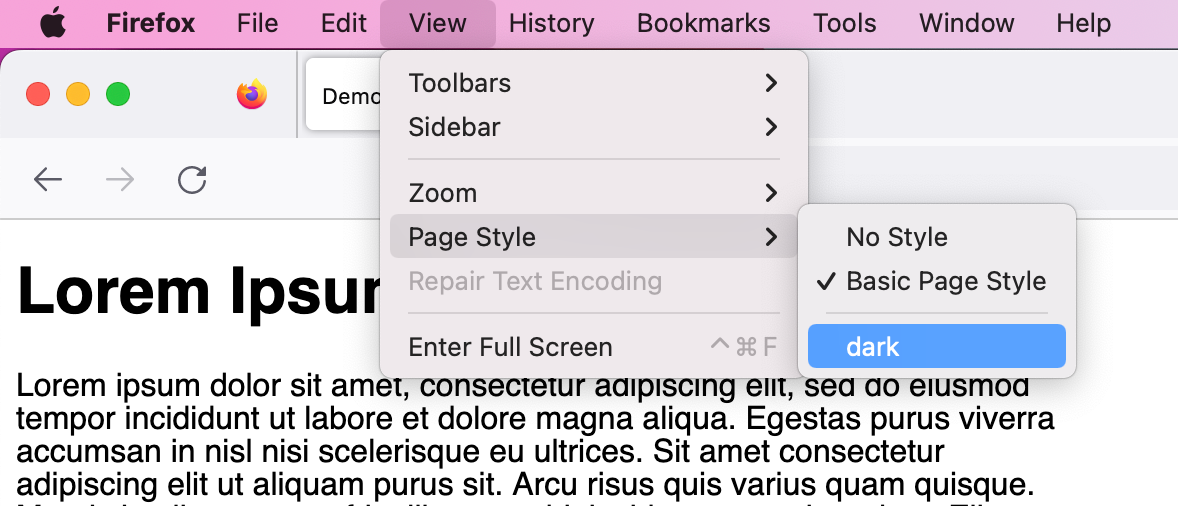
If it appears with a type attribute that has the value application/rss+xml or application/atom+xml, then the alternate keyword creates a hyperlink referencing a syndication feed (in RSS or Atom respectively), which is useful for crawlers to find more content. In this case, it is not an exact alternative for the document, but it provides additional information about it, making it great for autodiscovery.
It can work both in <link> and <a>, and the meaning is the same in both:
<!doctype html>
<html>
<head>
...
<link rel="alternate" type="application/rss+xml" href="feed.rss" />
<link rel="alternate" type="application/atom+xml" href="atom.xml" />
...
</head>
<body>
...
<a href="feed.rss" rel="alternate" type="application/rss+xml">
Subscribe to my feed and never miss a blog!
</a>
...
</body>
</html>This combination doesn’t impact our site’s visitors, but it provides us with control over how or what we want web crawlers to process our site. If there are multiple linked resources of this type, the first one is considered the main/default one, so the order would be important in that scenario.
In any other case, the alternate keyword indicates that the linked element is an alternative version of the current document. But it doesn’t end there: the attributes that accompany the rel will provide additional information about the linked resource.
media: can be used to specify the target devices (mobile, print, etc.) for the alternative version.type: used to identify what format (PDF, XML, etc.) the linked alternative version is available on.hreflang: defines which language (English, Spanish, etc.) the linked resource is in.
This opens a world of combinations and possibilities. Again, maybe not so much for the browser users, but definitely for bots and crawlers that need to process the information as accurately as possible.
<!doctype html>
<html>
<head>
...
<!-- alternative document versions in German, Spanish, and French -->
<link href="/de" rel="alternate" hreflang="de" />
<link href="/es" rel="alternate" hreflang="es" />
<link href="/fr" rel="alternate" hreflang="fr" />
<!-- alternative document version in Spanish in PDF, specific for printing -->
<link href="/es/print/" rel="alternate" hreflang="es" type="application/pdf" media="print" />
...
</head>
<body>
...
<p>
Thanks for checking out my online resume, feel free to download a
<a href="resume.pdf" rel="alternate" type="application/pdf">
PDF version.
</a>
</p>
<p>
<a href="https://m.link-to-our-site.com" rel="alternate" media="handheld">
Check out a mobile version of this site too!
</a>
</p>
...
</body>
</html>Remember: the order of the attributes is not important, but for some cases, the order of appearance of the tag may define which is more important or the default one.
author
This may seem like an easy one: the “author” rel is a hyperlink that will point to the author (it could be mailto: with an email). But there’s a catch, the author of what? the page? the content inside? what?
The answer to these questions will depend on where the author link appears: if it’s inside an <article>, then it will point to the author of the article, if it’s outside of an <article> then it applies to the document/page as a whole.
Let’s review it with an example:
<article>
<!-- Article content -->
<footer>
Written by <a href="https://janedoe.com" rel="author">Jane Doe</a>.
</footer>
</article>
<!-- rest of the page -->
<p>
Site created by <a href="https://johndoe.com" rel="author">John Doe</a>.
</p>The first link appears inside an <article> which let us know that the link is pointing to the author of the article (Jane Doe). While the second link is outside any <article>, which tells us that is the author of the whole page (John Doe). This could be convenient in sites with syndicated content (like blogs or newspapers), to set a difference between the article’s author and the site’s owner/author.
Another way of specifying the page’s author is having an actual <link> tag in the page’s <head> with the rel “author”. Then we know for sure that it applies to the whole page and not just to a part of it:
<!doctype html>
<html>
<head>
<link rel="author" href="https://alvaromontoro.com" />
...
</head>
...
</html>bookmark
This rel value can only appear in <a>/<area>. It identifies a permalink for the nearest ancestor <article> or section (which doesn’t necessarily have to be a <section> element). This last part can be confusing, let’s review it with an example:
...
<body>
<h1>James Bond Movies</h1>
<article>
<h2 id="no-time-to-die">No Time To Die</h2>
<p>
The twenty-fifth movie in the James Bond series. Daniel Craig was
James Bond in this installment.
</p>
<p>
<a href="no-time-to-die.html" rel="bookmark">Permalink</a>.
</p>
</article>
<div>
<h2 id="goldeneye">Goldeneye</h2>
<p>
A movie and an amazing Nintendo 64 videogame. The iconic Pierce
Brosnan played the role of James Bond on this movie.
</p>
<p>
<a href="goldeneye.html" rel="bookmark">Permalink</a>.
</p>
</div>
</body>
...The first link with rel= “bookmark” (permalink for No Time To Die) is inside of an <article>, so it will apply to that article in particular. The second link with rel= “bookmark” (permalink for Goldeneye) is outside of an <article>, applying to the closest section, which will be defined by the earliest ancestor with a heading.
Notice how, if the bookmark link is not inside an <article>, it can be a bit tricky to identify what section it applies to. It is more important than ever to use the right markup.
canonical
A canonical link specifies the preferred version of the document. This is really helpful if we cross-post content online: while a search engine indexes the pages, it will be able to identify the original version and not penalize the author for having duplicated content.
Many blogging systems (e.g., Medium, DEV, Hashnode, etc.) allow for specifying a canonical URL for the articles, and placing a <link> element with rel="canonical" just like this:
<!doctype html>
<html>
<head>
...
<link rel="canonical" href="https://path-to-preferred-url-version" />
...
</head>
...According to the HTML standard, it is only allowed on a <link> element, but the microformats definition mentions it on the <a> elements too. In my opinion, it would make sense to allow rel="canonical" in an <a> tag, but it could be problematic for publications. Better to stick to the HTML standard and only use canonical inside a <link> in the <head>.
help
This keyword can be used in all the available elements: <link>, <a>, or <form>. In all of them, it identifies a resource that contains help, the difference will be the scope of that help:
- In a
<link>, it will link to a help resource related to the document as a whole. - In an
<a>, it will be help related to the section that contains the anchor. - In a
<form>, it specifies that the target contains information about the form and its contents.
In the following example, the help link applies to the section that contains the label and input:
...
<form>
...
<div>
<label for="phone">Phone number</label>
<input id="phone" name="phone" />
<a href="phone-help.html" rel="help">(Help)</a>
</div>
...
</form>
...Browsers and assistive technologies can use this link to provide a more standard computer behavior. For example: historically, pressing F1 opens the help functionality; So they could open the linked resource if the special key is pressed while on the section to which the help link applies.
Also, in some cases, browsers may style the cursor differently if a link has the rel="help". (And if they don’t, it may be a nice feature to add by developers.)
icon
This rel value can only be used within a <link>, usually in the <head>, and it should link to an image. That image will then be displayed for representing the page in the user interface.
The rel="icon" can be combined with other attributes such as type, media, or sizes which will help the browser pick the most adequate icon for the user.
<link rel="icon" href="fav.ico" />
<link rel="icon" href="favicon.png" type="image/png" />
<link rel="icon" href="small.ico" sizes="16x16 32x32 48x48" />
<link rel="icon" href="large.ico" sizes="128x128 512x512 1024x1024" />
<link rel="icon" href="iphone.png" sizes="57x57" type="image/png" />
<link rel="icon" href="bw.ico" media="screen and (max-color:2)" />You might have found a rel value of shortcut icon (in that order) instead of just icon, that was the old way of writing it and browsers still support it for historical reasons, but there’s no reason to do that anymore.
Another thing that we find in the wild is a rel value of apple-touch-icon. This is a specific value for Safari, only supported on Apple devices. Feel free to use it if you want to provide specific icons for them, but remember that it is not a standard value.
license
The license value can be used in all the supported tags (<link>, <a>, and <form>) to create a hyperlink to the copyright license terms under which the main content is provided. Notice the term “main content” instead of “current document” that is used throughout the article. This is because the license applies to the content itself, and the page/template may have a different copyright or license.
The specification does not specify how to differentiate the main content from the rest of the content. The link with rel="license" must be presented in a way that makes it clear to the user what content it applies to.
The following example simulates a website with images/videos and the license hyperlink for one of the images:
...
<figure>
<img href="image.jpg" alt="Image for this demo" />
<figcaption>
An demo image for the article. License:
<a href="https://creativecommons.org/licenses/by/4.0/" rel="license">
CC BY 4.0
</a>
</figcaption>
</figure>
...The value copyright was accepted in the past as a synonym of license, and browsers still support it, but we should go with the standard license.
manifest
The manifest relationship can only happen in a <link>. It indicates that the linked resource is a manifest file with metadata related to the current document.
The manifest may contain information about the entry file to install the web application, the icons to use, the app’s name, theme colors… In this article, we won’t dig into how to use the manifest as our focus is exclusively on the rel attribute used to link it.
Here’s how you can link your manifest from the <head>:
<!doctype html>
<html>
<head>
...
<link rel="manifest" href="/manifest.json" />
...s
Two important things to remember about this rel value:
- Browsers will use the first
<link>withrel="manifest"in the tree order, ignoring any other that may appear. - Browsers will execute the manifest when they consider it necessary, never assume that the entry point script will be executed.
pingback
A pingback is a method for authors to get notifications when their content is linked. With pingback, we can provide the address of the pingback server that handles the pingbacks to the current document:
<link rel="pingback" href="https://alvaromontoro.com/pingback" />This can be useful, for example, to process the notification and add a note on the page (like WordPress does). It can also be helpful for SEO.
The pingback value can only be used in the <link> element.
search
The search keyword indicates that the linked resource provides a way of searching the document and its related resources. It redirects to a search page.
<p>
Read more about this topic by <a href="/search" rel="search">searching this
site</a> or <a href="https://google.com/search?q=rel+attribute" rel="search">
checking on Google</a>.
</p>Notice how it doesn’t have to be an internal search functionality. In the example above, one of the search links points to Google.
Some browsers allow adding plugins to their interfaces to provide custom searching features. If we have an OpenSearch plugin, we can link it using type="application/opensearchdescription+xml" alongside the search value to add the plugin easily to the browser.
tag
The linked resource contains information about a tag or keyword related to the current document. It can be a description, a list of other elements from the same category, etc. This rel value is only valid on a and area elements.
A practical use of the tag value could be seen on blogs or other sites where content can be categorized. StackOverflow is a great place to see links with rel="tag" working live. Or we could have something like this on our blog:
...
<article>
<h1>The Definitive Guide of Colors in CSS</h1>
...
<footer>
<h2>Tags</h2>
<ul>
<li><a href="/tags?t=css" rel="tag">CSS</a></li>
<li><a href="/tags?t=htm" rel="tag">HTML</a></li>
<li><a href="/tags?t=webdev" rel="tag">Web Development</a></li>
</ul>
</footer>
</article>
...The rel="tag" links apply to the whole page independently of where they appear within it. Even if they are located inside an article, they are not exclusive to the article itself.

Personal Types
They indicate a relationship between the author of the document/article and the linked resource (which should be an online profile). The HTML standard only has one of this type (“author”), but the XHTML Friends Network (XFN) defines many more:
author: see description in the meta types.crush: the linked page represents a person you have a crush on.date: the hyperlink is to a page about someone you are dating.friend: the link identifies a friend.me: this value became really popular with the rise of Mastodon. It is used to link to a page that represents the same person as the current document.muse: a link that identifies a person who inspires the person.
As you may imagine, there are many more values that could be used. Quite often, just using the English word for the personal relationship will work as a valid rel: colleague, child, acquaintance, neighbor, parent… all good.
Here are some of these personal rel values in action:
<h1>Welcome!</h1>
<p>
My name is <a href="profile.html" rel="me">Ross Geller</a>, thanks for
visiting my personal website!
</p>
<p>
I live in NYC with my buddies <a href="j-man.html" rel="friend">Joey</a>
and <a href="king-of-bad-thanksgivings.html" rel="friend">Chandler</a>.
In the same building block as famous cook (and my younger sister)
<a href="monica.html" rel="sibling">Monica Geller</a>.
</p>
<p>
Monica lives with <a href="rachel.html" rel="crush date">Rachel</a> and
renown musician <a href="regina-phalange" rel="muse friend">Phoebe</a>
(author of the smash hit "Smelly Cat").
</p>One last point about this personal type: only the “author” value is supported in a <link> tag, all the others are only allowed on <a>.
Processing Types
These types don’t indicate what the linked resource is or how it is related to the current document, instead, they tell the browser how the link should be treated or processed, creating a connection that may not be completely semantic but making it special.
All of these values are only accepted in the <link> element, they will normally appear in the <head>, and will mainly impact performance.
dns-prefetch
The dns-prefetch keyword indicates that the browser should preemptively perform DNS resolution for the specified domain. Basically, we are telling the browser that we will likely need some resources from the linked domain, so it will be beneficial and good for the user experience if it started resolving the address and getting ready to ask for files.
Using this type of rel reduces the latency when requesting an online resource and improves the overall performance, giving the impression that the content loaded faster (because some of the load work was done before it was actually needed.)
For example, if we are using Google Fonts, and we know that our page will at some point need the font, we can prefetch the CDN where Google hosts the fonts:
<link rel="dns-prefetch" href="https://fonts.googleapis.com">If you have used Google Fonts before, you might have noticed that it doesn’t use rel="dns-prefetch" but rel="preconnect" (we will analyze it soon). This is because dns-prefetch only performs DNS resolution, while preconnect does DNS resolution and also establishes a connection to the server, making the process faster.
Which raises a fair question: why even use dns-prefetch if preconnect does more? Because network connections are “expensive”. If we need sources from many third-party domains, preconnecting to all of them may impact performance negatively. Instead, it would be better to preconnect only to the more “urgent” ones and do a dns-prefetch for the rest. There’s no risk in using both together (even for the same domains!) and if for some reason the browser doesn’t support them, it won’t impact our site at all (apart from having to load a couple more lines of code.)
modulepreload
JavaScript code is getting bigger and bigger, and it is becoming more important to split the code and organize it into simpler modules that can be run when needed. NodeJS and some frameworks have their own methods for module usage, and some browsers provide native module functionality too. This is where the modulepreload value is important.
We can use rel="modulepreload" to preload a module script and place it in the appropriate module map without evaluating it (that will happen when it is required). This optimizes the module load, making the process more efficient.
<!doctype html>
<html>
<head>
...
<link rel="modulepreload" href="app.mjs" />
<link rel="modulepreload" href="record-player.mjs" />
<link rel="modulepreload" href="trade.mjs" />
<link rel="modulepreload" href="payment.mjs" />
<script type="module" src="app.mjs"></script>
...In the example above, we are preloading several scripts. The main module is executed (app.mjs), and the others will be available whenever they are needed (record-player.mjs, trade.mjs, payment.mjs).
modulepreload is basically a specialized version of the preload keyword (see below), as it applies specifically to one type of resource: script modules.
preconnect
As mentioned in the dns-prefetch section, with the preconnect keyword, we indicate to the browser that a resource from the linked domain will most likely be needed, and initiate a connection to its origin before the resource has even been found by the browser.
By doing so, we are increasing the network performance, because we are establishing a connection that will be ready when it’s needed, reducing the latency, and improving the user experience.
A practical example of preconnect can be found on Google Fonts: you may have noticed the code to embed fonts includes a couple of extra lines:
<link rel="preconnect" href="https://fonts.googleapis.com">
<link rel="preconnect" href="https://fonts.gstatic.com" crossorigin>
<link href="https://fonts.googleapis.com/css2?family=Roboto&display=swap" rel="stylesheet">The first two <link> use preconnect while the third <link> imports a stylesheet which will bring the font. Those first two lines initiate a connection for loading content from the Google CDNs, so the browser is ready to download the files.
prefetch
With prefetch, we identify a resource that may be used by the subsequent pages, telling the browser that it should fetch that resource to deliver a faster response when the navigation to those pages actually happens. The browser will proceed to load the content into the cache for later use.
Prefetching some files for later use–an image, some script, and a song:
<link rel="prefetch" as="image" href="super-important-image.jpg" />
<link rel="prefetch" as="script" href="code.js" />
<link rel="prefetch" as="audio" href="https://somecdn.com/music.mp3" crossorigin />The as attribute is optional, but highly recommended (see preload section for more details.)
Use prefetch carefully. It is a little bit of a “gamble”: we are fetching content that we presume the user will need soon, but if the user doesn’t navigate the way we expect it, we might have used bandwidth unnecessarily.
preload
With preload, we ask the browser to fetch some resources and process them as specified with the as attribute, because those files are important and we will need them on the current document.
In this example we will preload an image, a script file, and an audio file:
<link rel="preload" as="image" href="super-important-image.jpg" />
<link rel="preload" as="script" href="code.js" />
<link rel="preload" as="audio" href="https://somecdn.com/music.mp3" crossorigin />Notice the as attribute because it is not trivial. It tells the browser what type of resource is being linked so it can process it adequately. Without it, the browser may end up fetching the content twice (the same thing with the crossorigin attribute.)
So, how are preload and prefetch different? While they seem to do the same, there’s a key difference: prefetch is used for “lower priority” resources that will be needed at a later time, and preload is for “higher priority” content that will be needed sooner (as on the same page, but that may have not been discovered by the browser yet.)
I will end this section by giving a piece of advice: do not preload everything. Quoting The Incredible’s supervillain Syndrome: “When everyone is super, no one will be.” If we preload every file that we will need, then there won’t be a real gain (and it may even be counterproductive). Be selective with the content to preload, and consider using prefetch or preconnect.
prerender
prerender works similarly to prefetch but at a larger scale. The linked resource may be a page, and it is not only prefetched but also processed (including its content) and rendered, caching the result until it’s needed.
Imagine that you created a multi-page form. You may want to prerender the next step because the user should logically navigate to it:
<link rel="prerender" href="form-step-2.html" />As with prefetch, prerender could be a bit of a “gamble” (even more this time): if the user doesn’t navigate the site the way we expect or if they leave the site completely, we will have fetched and processed content unnecessarily.
stylesheet
Surprised to see this value as part of the processing types? I considered adding it to the meta types, but it fits here better.
The stylesheet indicates that the linked resource contains styles for the page, so it provides a little semantics; but it does much more: browsers know that stylesheets are a key part of the page’s presentation and, unless the alternate keyword shows up too, it also knows that it needs to process the styling file and apply it to the page. The stylesheet keyword is telling the browser how to treat the linked file.
Its basic use is simple: only in <link>, the rel="stylesheet", and an href pointing to the stylesheet file. We can also use other attributes (media) to change the default behavior and when the styles will be applied:
<!-- this file will be automatically downloaded and applied -->
<link rel="stylesheet" href="my-super-cool-styles.css" />
<!-- this one is downloaded but not applied -->
<link rel="stylesheet alternate" href="prototype.css" title="prototype" />
<!-- this one is downloaded but only applied when printing -->
<link rel="stylesheet" href="printer.css" media="print" />Network Types
The “network types” specify the type of connection that the document and the linked resource have as well as the information that will be shared between them.
They don’t create a link, they annotate it, making it easier for crawlers and spiders to index the content appropriately. As they will have more information about the nature of the connection.
external
A resource is external if it is not part of the current site. We can easily identify them by adding a rel="external" to it, which is allowed on <a>/<area> or the target in a <form>, but never on a <link>.
<!-- on a personal blog -->
<a href="https://en.wikipedia.org/wiki/Cat" rel="external">Read about cats</a>This doesn’t give much information to the browser (it is transparent for it), but it can be convenient for developers to use CSS attribute selectors and style these links differently:
/* add a small icon behind each external link */
a[rel="external"]::after {
content: url(external-icon.svg);
margin-left: 0.5rem;
vertical-align: middle;
}nofollow
A nofollow rel value on a link tells the crawlers to “ignore” the linked resource because it is not endorsed by the current document’s owner, or that it was included because of a commercial relationship.
It is an important value for Search Engine Optimization (SEO): if your page links to low-quality content, your site’s credibility (and its ranking in the search engines) may suffer. Using nofollow won’t penalize your site:
<a href="https://totallynotmischivieoussite.com" rel="nofollow">
This is a link created by an user
</a>Using rel="nofollow" in user-generated content and links is a must. You never know what they are going to share, and you don’t want to end up on the losing side of a spamming scheme.
noopener
A link may have access to the previous page by using window.opener depending on how it was opened (e.g. if it has target="_blank"). This is a potential security problem and it could lead to other issues like phishing attempts.
To avoid these situations, we can use noopener value in rel to open the new document without granting it access to the document that opened it:
...
<div class="comment">
Check my <a rel="noopener" href="https://no-good-phishy-site.tk">site</a>
</div>
...As with nofollow, the main target for this value will be user-generated content that we don’t want to provide with extra information.
noreferrer
noreferrer is really close to noopener. In fact, it does the same thing as noopener (it doesn’t grant access to the document) plus it tells the browser to omit the Referer header when opening the link. This way, the linked resource cannot access the referrer’s information (e.g., its address).
This provides an extra layer of anonymity and security. The linked resource will not see a referrer, looking like the request came from direct traffic to their site instead of from the originating link.
...
<div class="comment">
Check my <a rel="noreferrer" href="https://no-good-phishy-site.tk">site</a>
</div>
...noreferrer and nofollow are often used together, to ensure that one is applied in case the other one is not supported by the browser.
opener
This is effectively the opposite of noopener. It doesn’t add that extra layer of protection when following the link by allowing it to access the opener.
<a href="./help-page.html" rel="opener">You have access</a>Sequential Types
These values indicate that the current document is part of a series or sequence and specifies the relationship of the linked resource with it. They have a big impact on user experience, accessibility, and SEO.
The HTML Living Standard only has two values related to sequences: “next” and “prev”, but there are some interesting ones defined in previous versions of the standard that are listed by IANA and microdata too:
next: indicates that the linked resource is the next in a series.prev: refers to the linked document as the previous in a series.previous: this value is a synonym of “prev”. It isn’t valid anymore, so we should avoid it, but browsers may still treat it as a “prev” for historical reasons.first: identifies the linked document as the first in a series.last: indicates that the linked resource is the last in a series.contents: the linked document is a table of contents. Some agents may use the synonymtoctoo.archives: links to a collection of records or materials of historical interest for the document.up: refers to the parent/upper category of the current document. Not necessarily in a sequence, but it shows some hierarchy.
Here’s a practical example of how it could be used to create pagination:
<nav aria-label="course index">
<ul>
<li>
<a href="toc.html" rel="contents">Table of Contents</a>
</li>
<li>
<a href="lesson-1.html" rel="first">Lesson 1</a>
</li>
<li>
<a href="lesson-2.html">Lesson 2</a>
</li>
<li>
<a href="lesson-3.html" rel="up">Lesson 3</a>
</li>
<li>
<a href="lesson-3.1.html" rel="prev">Lesson 3.1</a>
</li>
<li>
<a href="lesson-3.2.html" aria-current="page">Lesson 3.2</a>
</li>
<li>
<a href="lesson-3.3.html" rel="next">Lesson 3.3</a>
</li>
<li>
<a href="lesson-4.html">Lesson 4</a>
</li>
<li>
<a href="lesson-5.html">Lesson 5</a>
</li>
<li>
<a href="lesson-6.html" rel="last">Lesson 6</a>
</li>
<li>
<a href="glossary.html" rel="glossary">Glossary</a>
</li>
</ul>
</nav>In this example, we have a navigation with eleven links to the table of contents, each of the six lessons (plus three “sub lessons”), and a glossary page. Many of those links have been extended using the rel attribute and provide helpful information to the browser and assistive technologies.
One perk of using “next” and “prev” with a <link> is that the browser may preload the linked documents to reduce the perceived load time, assuming that the user will most likely move forward/backward within the series.
<link rel="next" href="https://link-to-next-in-series" />
<link rel="prev" href="https://link-to-previous-in-series" />In the past, Google used the “next” and “prev” links to index the pages accordingly, but that is no longer the case. This doesn’t mean you should stop using those values: they are still helpful for accessibility, and other search engines may index based on them. Google is dominant but not the only one.
Conclusion
As you may have noticed by this really long article, the rel attribute is anything but trivial. It plays an important role in providing meaning to the links, taking the Internet to the next level semantically, and boosting your site’s performance through the roof.
If you made it here (did I already mention that this article is really long?), take a few more minutes to check other resources with more details and better explanations (Addy Osmani’s article is simply amazing.)
Thanks for reading!
Bibliography
<a>: The Anchor element, on MDN Web Docs.<area>: The Image Map Area element, on MDN Web Docs.<form>: The Form element, on MDN Web Docs.<link>: The External Resource Link element, on MDN Web Docs.- Existing rel values, on the microformats wiki.
- HTML Attribute: rel, on MDN Web Docs.
- Link Relations, on the Internet Assigned Numbers Authority (IANA).
- Links, on the HTML Living Standard.
- Pingback 1.0, by Ian Hickson.
- Preload, Prefetch And Priorities in Chrome, by Addy Osmani on Medium.
- Preload, Preconnect, Prefetch: Improve Your Site’s Performance with Resource Hints, by Niko Kaleev on Nitropack.
- Resource Hints (Working Draft), by Ilya Grigorik on the W3C.
- XFN 1.1 relationships meta data profile, on the GMPG.
About Álvaro Montoro
Alvaro Montoro is a Software Engineer from Spain who lives in the United States. He enjoys playing with web technologies (especially HTML and CSS) and testing what's possible to do with them.
Website/Blog: alvaromontoro.com/blog
CodePen: alvaromontoro
Mastodon: @alvaromontoro@front-end.social